Sitecore 7 in-depth: Indexing mechanics

Yesterday, all European MVP's got the chance to meet with part of the Sitecore 7 development team at Sitecore's UK office in London for an in-depth insight in Sitecore’s new search features.
It was a fantastic session that went really deep into the mechanics of the search and we were left with a brain full of new information and almost no questions to ask.
I really want to share as much information as possible about the new features, but it is a lot to take in all at once!
Therefore it will be split it into multiple blog posts.
Before I start, I need to give all credits for the information you're about to read to Tim Ward, Stephen Pope and Martin Hyldahl (in no particular order) as they were the ones that told us all about it and shared their slides with me.
It also needs to be noted that those three developers with the addition to Alex Shyba are the ones that developed the new search abstraction layer in an amazingly short time frame.
Hats off to those guys!
1. Search Abstraction Layer
I just threw around this term already; the new search features are shipped as an abstraction layer on top of the existing kernel.
This means that no changes have been made to the kernel to facilitate the new search, but also (and this is really neat) that it works completely detached from Sitecore.
You can create a solution, add references to just the Search DLL’s and every feature will work, without Sitecore!
It allows you to index stuff like the file system, external databases and other data sources that have nothing to do with Sitecore and it is very easy to unit test.
2. Metrics
These numbers have been floating around on the web for a few weeks, but I just added them to be complete.
In Sitecore 6.6, indexing 10 million items took 27 hours.
In Sitecore 7, it takes 98 minutes with Lucene and 70 minutes with SOLR.
If you look at searching through that index, in Sitecore 6.6 it would take 3.9 seconds before all results came back.
In Sitecore 7 it takes only 0.3 seconds and that is including all facets!
It’s an amazing improvement and I’m going to explain how it all works.
This blog post will focus on the mechanics behind indexation.
Later posts will focus on searching and configuration.
3. Overview of the indexation process
I will first show you all the steps that are executed during indexation and then describe each of them in more detail. If you want to jump to the detailed description, just click on the step below.









3.1 Rebuild (drop) index
Not really much to explain here, this is the start of the process; something triggers a rebuild of the index. There are a few strategies for triggering indexation: asynchronous, synchronous and event-based (working with the EventQueue).
One important new possibility is to rebuild the index without removing the existing index first!
In the past, a rebuild would mean the old index would be removed first and the search was unavailable.
So that is solved now, although it’s not configured as default (at this point).
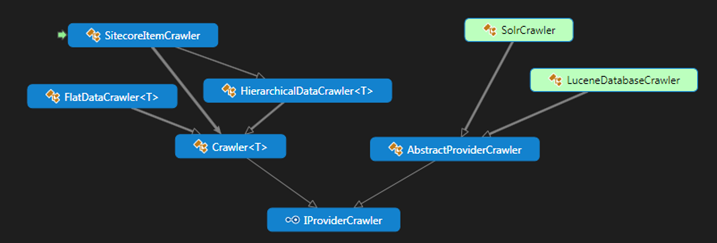
3.2 IProviderCrawler
The development team went for a provider based approach when they created the search layer.
The IProviderCrawler interface is new and all crawlers are based on this.
If you are going to implement your own functionality here, you probably want to inherit from the LuceneDatabaseCrawler or SolrCrawler class.
It must be noted that the crawler does not necessarily needs an Item object to index, but rather an IIndexable, which can be any kind of data you’d like to index.
3.3 Field Reading (Document Builder)
During this step, field values are read from the indexable object.
The step itself is split into different tasks (although I’m pretty sure not in this particular order):

3.3.1 Special Fields
Special fields are really not that special, they are just explicit mappings for built-in index fields on the document. I say explicit, because you should not add all your fields this way as most of them will be added using Field Readers.

3.3.2 Computed Fields
Computed field values are computed by external code and set up like this:
<field fieldName=”istemplate” returnType=”bool”>Sitecore.ContentSearch.ComputedFields.IsTemplate, Sitecore.ContentSearch</field>3.3.3 Copy Fields
Copy fields can be configured to take the value of a field, transform it and store it in another field.
For example: you take the _Created field which contains “20130411T120000” and using the copy field configuration you store it in the index as _smallcreatedate and transform the value to: “20130401”.
3.3.4 Field Reader
Field readers are configured on Field Type basis.
So you can take all string type fields (e.g. Single-Line Text, Multi-Line Text, Text, etc.) and process them with the same field reader.
Number fields would be processed by another field reader, and so forth.
3.3.5 Include/Exclude Fields
This task determines if fields need to be in- or excluded from the index.
3.4 Value Formatting / Type Converter
During this step, values will be taken from the indexable object and processed by a Type Converter.
Which converter is used is based on the Field Type.
For example, a GUID field value {B6FBE819-3334-4873-BA60-02247FD0C5D8} will be converted to b6fbe81933344873ba6002247fd0c5d8, which is an index ready format.
Sitecore 7 ships with built-in type converters for all default Field Types and you can obviously build your own.
3.5 Field Name Translator
Lucene does not accept spaces in field names, SOLR has some other guidelines for field names and another system would have yet another guideline.
So we need to convert our field name, which is done by the Field Name Translator.
“A field nAme wITH spaceS” will be translated to “a_field_name_with_spaces” when you use Lucene.
Using SOLR, the field name “Title” will be translated to “title_t”.
3.6 Analyzer Mapping
Next up: setting up analyzers.
This can be done based on several criteria, for example based on a specific language version, but also on a field name basis.
So you would setup a different analyzer for Japanese items than you’d use for English.
3.7 Pipelines
There are a few tasks that are now handled by pipeline processors.

3.7.1 Boosting
I guess the name says enough, this is where you determine if an indexable object needs to be boosted in the search results later on.
3.7.2 Inbound filters
In here you can determine if you want the indexable object to be added to the index or excluded.
3.7.3 Dependencies
These processors are used to retrieve indexable objects that you currently indexed object depends on. For example, presentation details, data sources or media items.
3.8 Document Indexed
Okay, at this point, our document is indexed!
But only in-memory, not yet on disk.
There is still one last step that needs to be executed before it’s stored on disk.
3.9 Commit Policy
You can configure a commit policy, which is basically a very last-minute check to determine whether or not your document should be added to the index.
It’s also used to prevent all documents from being written to the index at once, which would cause a huge spike in your disk I/O.
3.10 Index Property Store
Once the index is completely rebuild and written to disk, there are some statistics written to the property store of the index.
Things like rebuild date, rebuild duration, etc.
4. And that’s how it’s done!
There you have it!
The entire process that is executed when rebuilding a search index in Sitecore 7.
I probably left out some of the details, because it was really a lot of information that we got in a very short time frame, but most of it is in here.
If you have any questions about it, don’t hesitate to contact me, because I’d love to answer them!